Models
To access and create model configs, navigate to AI > Model.
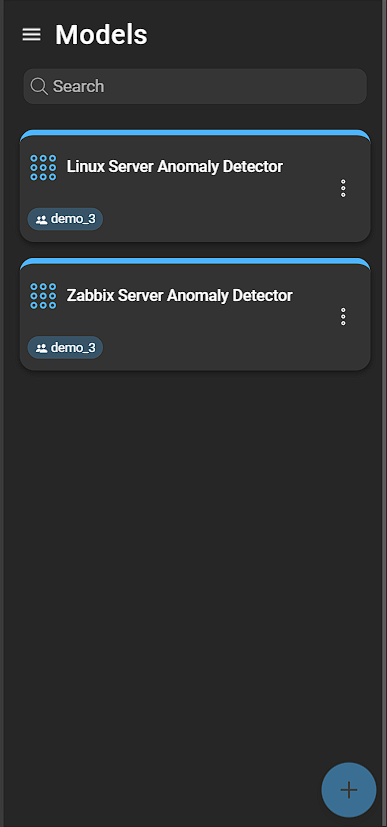
Creating model configs
To create a model config, click the blue plus button. This opens a form:
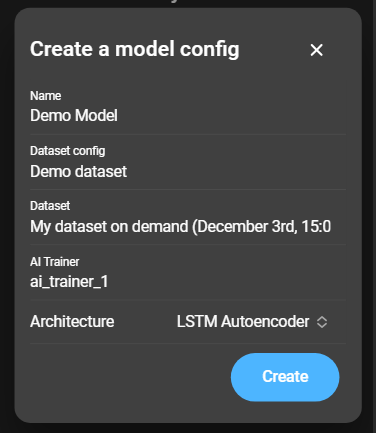
- Name: Name of the model config.
- Dataset config: Dataset config to access a dataset.
- Dataset: Dataset of the provided dataset config.
- AI Trainer: Microservice to use as AI Trainer.
- Architecture: One of two available architectures: LSTM Autoencoder or GRU Autoencoder.
Click Create to continue.
Configuring model configs
To access the config of a model, click an entry in the list. A model config consists of several options:
General
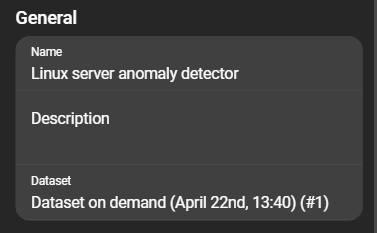
- Name: Name of the model config.
- Description: Description of the model config.
- Dataset: The dataset on which the model is trained. Click to select another dataset available in the selected dataset config.
Architecture
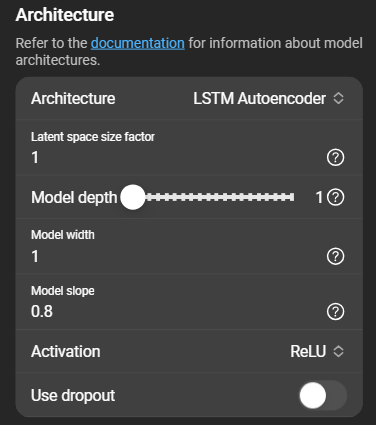
- Architecture: Selected during creation. Can be changed here along with the latent space size factor.
- Latent space size factor: Multiplied with the number of features to determine the size of the latent space.
- Model depth: Number of layers of the encoder and decoder.
- Model width: Multiplied with the number of features to determine the base number of neurons in an encoder and decoder.
- Model slope: Factor between
0and1that determines how steep the encoder and decoder layers approach the latent space. - Activation: Select between ReLU or Sigmoid .
- Use dropout: Only used during training. When enabled, a layer is inserted that randomly deactivates connections between neurons to prevent overfitting .
Training
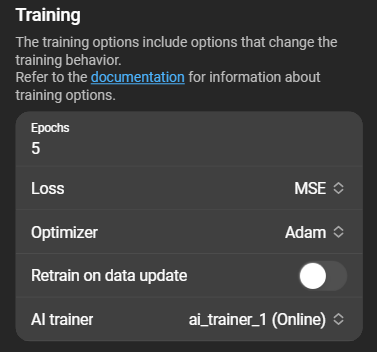
- Epochs: Number of epochs to train.
- Loss: Function to evaluate model performance.
- Optimizer: Optimization algorithm: SGD (Stochastic Gradient Descent) or Adam .
- Retrain on data update: Toggle to retrain the model when a new dataset is extracted.
- AI Trainer: Currently selected AI Trainer.
Preprocessing
Options to adjust the hyper-parameters of the model.
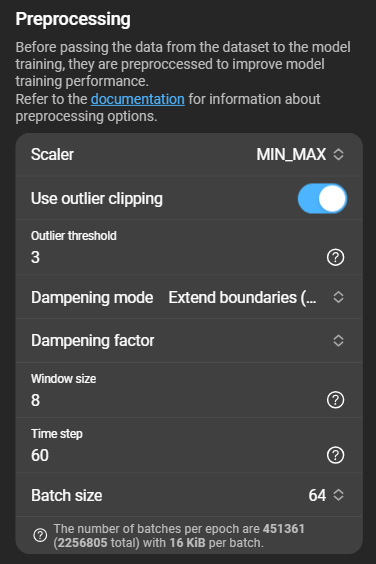
- Scaler: Currently only the MIN_MAX algorithm is supported.
- Use outlier clipping: Toggle to exclude extreme values.
- Outlier threshold: Threshold for clipping values. Smaller values mean stronger clipping and should not fall below
1. Recommended value:3. - Dampening mode: One of three modes:
Use training boundaries (No Dampening),Extended boundaries (Dampening),Always Clip (Infinite Dampening). - Dampening factor: Available only if dampening mode is set to
Extended boundaries (Dampening). - Window size: Number of time steps considered for one model step.
- Time step: Interval (in seconds) between rotations of the sliding window. Must be less or equal to the smallest interval of an item in the dataset to prevent loss of data.
- Batch size: Determines the number of batches based on batch size, time step, and dataset duration.
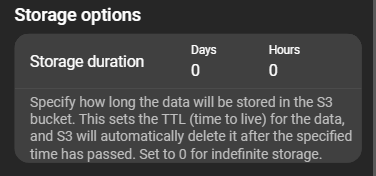
Storage options
Storage options organize models by retention period. Define how long a model is kept in days and/or hours. If older than the defined time, it is deleted.
Models
Generate and view models in this section.
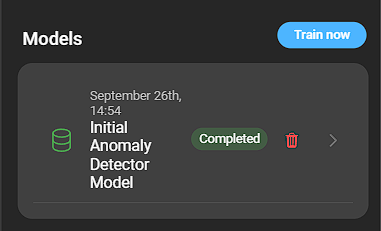
Create model
Once configuration is complete, click Train now to create a model. The model appears in the list and can be inspected by clicking it.
Model details
The status and name of the model are shown at the top of the page. A model can have two states: Training completed and Training incomplete.
As long as the model is being trained, only limited information is visible. Once the model has the status Training completed, additional information is displayed.
Model configuration
This section shows all configurations used to train the model. Essentially, a summary of the dataset and model config at training time.
Model tests
Once a model is fully trained, it can be tested immediately on previously extracted datasets to evaluate the loss.
Click Create new test to open a dialog:
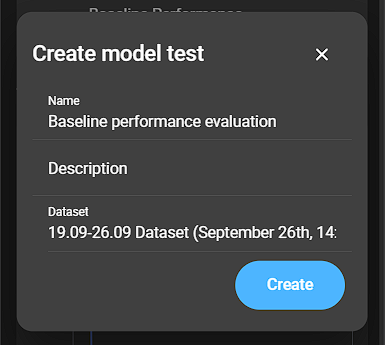
- Name: Name of the model test.
- Description: Description of the model test.
- Dataset: Dataset for the model test.
Click Create to finish the process.
After the test is created, Prisma applies it to the specified dataset. Results can be viewed in the test details, accessible by clicking the test.
Model test details
This page shows the status, name of the test, and three sections: General, Evaluation loss, and Job log. The status can be Test completed or Currently training.
General
Displays the dataset used for testing.
Training loss
Overview of how accurately the model processes data. For the supported loss functions, smaller values indicate higher accuracy.
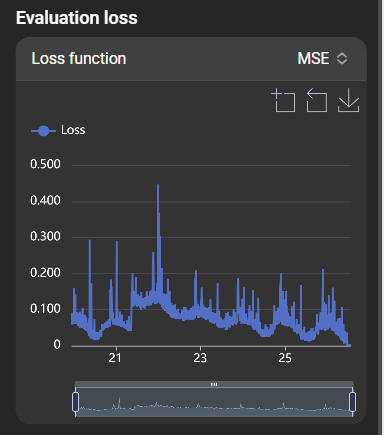
The loss function can be selected in the top right to see its effect on evaluation:
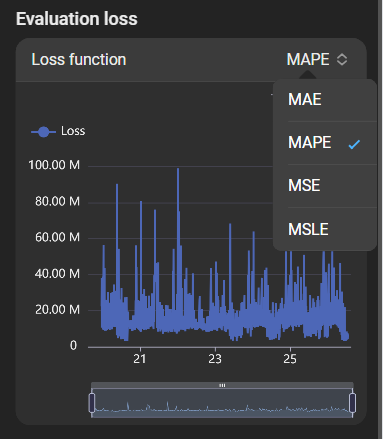
Job log
A completion bar at the top shows test progress. The job log lists each step carried out to test the model. Steps can be expanded for details.
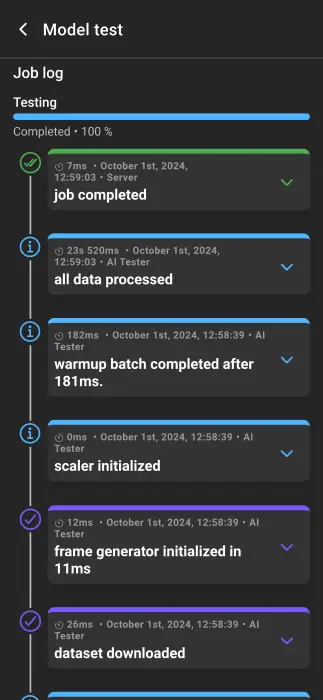
- Processing time: Duration of the step.
- Date and time: When the step was processed.
- Type: Event type.
- Event: Event name.
- Microservice: Responsible microservice.
- Full event: Full event stack trace.
Training loss
Shows model performance during training relative to loss. The x-axis indicates the number of batches trained.
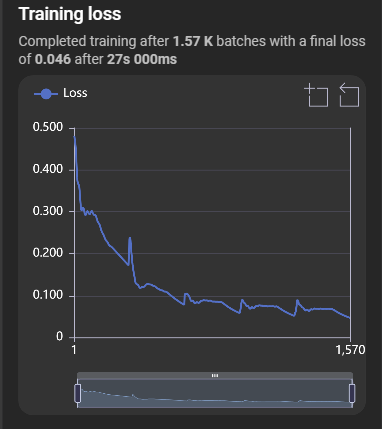
Hovering over a datapoint provides additional details.
The graph supports zoom, reset zoom, and save as image. A bar below the graph also provides data zoom with start and end values.
Job log
A completion bar at the top shows training progress. The job log lists each step carried out to create the model. Steps can be expanded for details.
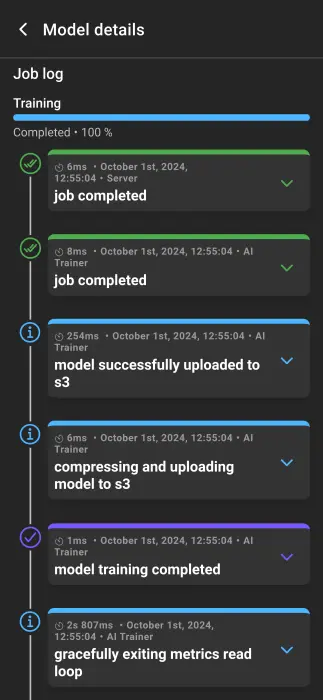
- Processing time: Duration of the step.
- Date and time: When the step was processed.
- Type: Event type.
- Event: Event name.
- Microservice: Responsible microservice.
- Full event: Full event stack trace.
Delete a model
Delete a model by clicking the bin icon.